Open-Sourcing Bloom: A REST API Caching Middleware
This article is a word-for-word repost of Announcing Bloom: A REST API Caching Middleware [https://journal.valeriansaliou.name/announcing-bloom-a-rest-api-caching-middleware/] from the blog of Valerian Saliou [https://valeriansaliou.name], Crisp CTO. -------------------------------------------------------------------------------- Premature optimization is the root of all evil. Especially when you launch a new SaaS business you're not sure will succeed and get the traction you would expect of


This article is a word-for-word repost of Announcing Bloom: A REST API Caching Middleware from the blog of Valerian Saliou, Crisp CTO.
Premature optimization is the root of all evil. Especially when you launch a new SaaS business you're not sure will succeed and get the traction you would expect of it. But, if success happens, you end up needing to optimize quite a lot of stuff.
Two years ago, Baptiste Jamin and I started Crisp, a Customer Messaging service with the initial goal of making Live Chat affordable for the smallest companies, even non-VC-funded startups. We succeeded towards this goal, and quickly scaled the product to embrace the larger Customer Support market, with more advanced features. We're proud to say we now have more than 20k users, of which 10% are paying customers (which is, to my sense, pretty good for a business based on the freemium model — it has been quite a hard journey though).
Today, I'm announcing Bloom, a REST API Caching Middleware, which will be soon plugged to our production platform at Crisp to reduce the load of our API system. Bloom is Open-Source, in the hopes it can help other SaaS / non-SaaS businesses reduce costs on their backend, shut down a few servers, reduce the sys-admin human cost, and as a bonus: lower their energy footprint. Bloom is our first effort towards Open-Source; Crisp is 100% built on OSS technologies, thus we feel we have a responsibility to give back.
Quoting what Bloom is from the GitHub page of the project:
Bloom is a REST API caching middleware, acting as a reverse proxy between your load balancers and your REST API workers.
It is completely agnostic of your API implementation, and requires minimal changes to your existing API code to work.
Bloom relies on Redis, configured as a cache to store cached data. It is built in Rust and focuses on performance and low resource usage.
The Bloom name comes from the analogy between a cache and the way flowers blossom. A cache starts empty, and then quickly populates with fresh data. Likely, flowers grow their petals from nothing.
First, let me put a little bit of context on this project, by explaining why we decided to start Bloom. Then I'll enumerate the features, go in the technical overview of the project and explain what drove our architectural choices.
The Why: What Made Us Build Bloom?
Context
Crisp is a Customer Messaging service, used by companies to provide support and keep in touch with their customers (eg. answer chats, emails, messages from Messenger, Twitter & Telegram, manage their user database, send campaign emails for marketing purposes, etc.). Crisp provides a chatbox for companies to setup on their website, as well as a wide range of integrations (inbound email, social networks, etc). It centralizes all the communication in a collaborative team inbox where operators / agents can reply (eg. from Web, Desktop, or Mobile apps).
So, there's 2 major sections in the Crisp product (amongst others): the website visitor chatbox, and the operator apps. Bloom solves a scale issue related to the operator apps; we'll come to this soon.
The Crisp backend is built on the top of the NodeJS platform, which allows us to quickly iterate and add new features, while keeping the (human) maintenance cost on older features low. NodeJS is used to run JavaScript on the backend, which is an interpreted and garbage-collected language. It's not strongly-typed and can be a bit heavy at scale. We don't regret our choice of NodeJS though (and more generally of interpreted, VM-based languages), as it provides us a high development throughput and low human time cost, at the expense of much larger hardware requirements (compared to compiled platforms, eg. Golang). More generally, Crisp is built on a micro-service topology, which we embraced from day 1. This topology always guaranteed the highest service availability for our customers and users. Thanks to that we rarely failed or went offline, or lost chats (which is critical when you sell a communication service / software) — [By the way, the Crisp micro-service topology will be the subject of a later post].
One core component of our infrastructure is the REST API, which is used on a day-to-day basis by our users answering chats and email from their own users, right from the Crisp Web app, Desktop apps, or mobile apps. The API is also consumed by some of our users who integrated Crisp to their own backend, doing calls to our API using eg. our NodeJS or Golang API libraries — for a wide range of actions, such as importing their user base into Crisp when an account gets created on their platform. Finally, the same API is used by our plugin platform, integrating Crisp to other platforms (eg. when you use the Slack integration of Crisp, you'll hit our API at some point, though indirectly).
The Crisp API handles more than 20 million HTTP requests in peak days (this totals to a whopping half a billion API requests per month, adjusting for days with lower traffic). Certain requests are very light, although others are quite expensive to process for our backend servers. We have only 3 DigitalOcean droplets costing $5/month running the API, so this totals to $15/month to run just that specific system (which is quite a low cost for the volume and nature of served requests) — I didn't account for the front NGINX load balancer, which is used for many other systems of our platform.
The API exposes a lot of routes, some of which are heavily used, eg. those regarding conversation management. Our REST API docs page is quite long, which illustrate how thick our API system is. So, managing fine-grained cache rules on a traditional cache layer can be tedious, one tends to forget to add or remove rules when API routes get added or removed.
Problem
Over time, we noticed a CPU usage increase from our API system, as we scaled and acquired more users, while other micro-service CPU usage stayed steady; even if they incidentally received more work with our growth. Thus, we plugged 2 more API servers to the platform and kept perceived performance good enough for our users, but the overall CPU usage is still growing for a steady RAM usage. Rather than plugging in even more servers, we decided to fix the issue at its root. Thus, we started searching for the bottleneck. We found out that Mongoose was the origin, and more specifically the underlying MongoDB BSON—JSON serializer / deserializer. MongoDB is used to store conversations, so there are a lot of calls to the MongoDB serializer / deserializer when our users are engaged in conversations with their own users.
At peaks hours, the instant CPU usage amongst our 3 API shards can hit ~80% with a mean of 50%, which leaves very little space to handle unusual traffic spikes (eg. a lot of users connect at the same time, or a short DOS happens). You'd say, "all right, add more servers then", which is a valid argument. Though, adding more servers would only hide the problem, as someone malicious crafting expensive requests and distributing it amongst a large amount of fake Crisp accounts could still slow things done at scale (note that we've worked on multi-layered rate limiting rules to prevent that). Plus, it's definitely a sys-admin burden that we're not ready to take, as we already run a total of 20 servers, and counting (managed by a team of 2 developers).

Notice that we do use the swap disk quite extensively on this worker server (SSD disks in our case). Though, most data on disk is not that frequently accessed (we do monitor disk I/O). This allows us to optimize our server costs nicely (RAM is expensive, SSD is cheap; but: SSDs are fast and most of the RAM data that goes to swap is inert). Also, RAM doesn't fluctuate a lot, so the only metrics to look at here are the CPU usage and mean system load, which are not optimal.
Solution
Replacing MongoDB and Mongoose wasn't an option for us, as those are the perfect "tuple" for the kind of service we operate, ie. storing messages as documents with loose object schemas.
Thus, we stumbled upon the idea of caching CPU-intensive routes, if not all HTTP GET & HEAD routes.
Using the NGINX internal caching layer was deemed not appropriate, as it is only time-aware (you set an expire TTL on what you cache, that's all). Crisp, being a chat service, needs fine-grained cache control: when an user opens a conversation on Crisp, and sends a message in that conversation, the cache that may have been generated on the first access is stale and should not be used on next request, no matter when it was set to expire. When the user refreshes their Crisp app, an updated conversation with the sent message should show. Fine-grained cache control should be achieved by workers in our micro-service topology, explicitly telling the cache system to empty cache for this specific conversation when a message insert occurs. This is obviously impossible with existing caching layer on the market, as it requires to be deeply integrated with the internals of the system.
Thus, the Bloom idea came up. Bloom should be a lightweight cache layer that sits between the load balancers (eg. NGINX) and the API workers (eg. written in NodeJS), letting HTTP POST, PATCH, PUT, OPTIONS pass through while caching HTTP GET, HEAD when deemed appropriate. Workers on the micro-service infrastructure should open a control channel to Bloom through which they can issue cache purge commands (eg. "clear the cache on that API route for this user"). The API should have fine control over what to cache and what not to cache via Bloom-specific HTTP response headers, that Bloom intercepts from the API response.
Security is not an option. Cache leaks amongst different authenticated API users (eg. different Crisp accounts hitting the same API), should be prevented by-design. Also, by default all cached data should expire after a while if not explicitly purged via the control channel. This prevents data from accumulating in the cache over time even if valid, and thus prevents the exposure of a huge amount of information in case of cache database leak (eg. a server hack where the cache storage is dumped from RAM).
The How: How To Do Caching For A Chat API?
Constraints
Two important statements hold true for any API that serves chats (or dynamic / active / living content):
- A few conversations are very active in the moment (cache becomes stale at every message, or event) — those are also accessed frequently, while the majority is not active anymore (old, closed conversations) — and thus are not accessed often.
- Conversations are grouped into inboxes, which are visible only to members (aKa operators) of this inbox (on Crisp, we call the "inbox" a "website"). Some served resources contain data specific to the authenticated user account.
Thus, the following 2 guarantees should be enforced on the cache system of such an API:
- Cache can be purged programmatically, upon update of a current conversation, while a past conversation can be set to expire by itself in a far time in the future (not too far though). Cache can be grouped in named buckets (think of it as "tags"), for the backend to expire it bucket-by-bucket via a control channel (eg. a Bloom integration for NodeJS).
- Cache should be routed by URL (thus you can put the "inbox" identifier in the URL), but more importantly by HTTP
Authorizationheader (thus you can be sure there is no cache leak depending on the inbox URL from authorized to non-authorized API consumers). You then have a cache routing namespace in the tuple format: (route<uri + query_params>,authorization).
Security
You'd wonder why caching based on the HTTP Authorization header? The reason is quite obvious: the HTTP Authorization header is used by REST API as a container for an username and password (usually only a password with an empty username). This header value is different for every API user account, and is typically generated as a long-living token that is unique to an user. Thus, a leak of the Authorization header would allow anyone to consume the API as the user the leaked token belongs to (whether Bloom is used or not). Thus, we can consider it is secure enough to serve a cached response on the basis of this header, without hitting the API user authentication system to validate this header on each request (which the API system does by itself, eg. to check if the route being consumed can be accessed by the current user — in the case of Crisp, "is this user allowed to access this website chat inbox?").
It's important to put an emphasis on shielding against any attack surface leading to cache leaks, which ultimately comes down to protecting user data. Thus, in addition to storing cache per-route and per-authorization (this gives an unique cache key), the underlying hashing algorithm used for internally compressing those keys should have a sufficient number of bits and a low probability of collision (collision attacks are easy on very small key hashes, eg. you may find one A and one B so that HASH(A) = HASH(B) = NAMESPACE_KEY, thus B may allow an attacker to read cache on A even if he doesn't know A), while staying compact and fast enough. Bloom picked the farmhash 64 bits hashing function, which has enough bits to theoretically store 2^64 = 1.844674407E19 keys (in practice less if we account for probable collisions below that number; plus, it is not a cryptographic hash function) and is designed for hashtable-like implementations.
Bloom as a Caching Middleware
Technical Approach
Bloom is hot-plugged between our existing Load Balancers (NGINX), and our API workers (NodeJS). Is is used to reduce the workload and drastically reduce CPU usage in case of API traffic spike, or DOS attacks.
As stated above, a simpler caching approach could have been to enable caching at the Load Balancer level for HTTP read methods (GET, HEAD, OPTIONS). Although simple as a solution, it would not work with a REST API. REST APIs serve dynamic content by nature, that rely heavily on Authorization headers. Also, any cache needs to be purged at some point, if the content in cache becomes stale due to data updates in some database.
How Does It Work?
Bloom is installed on the same server as each of our API workers. As seen from our NGINX Load Balancers, there is a Bloom instance per API worker, which NGINX points directly to. Bloom then points to the underlying API worker. This way, our complex Load Balancing setup (eg. Round-Robin with health checks) is not broken. Also, we don't create a SPOF (Single Point Of Failure) by setting up Bloom as 1 API worker = 1 Bloom instance, upon which NGINX can perform its health checks as usual. Each Bloom instance can be set to be visible from its own LAN IP our Load Balancers can point to, and then those Bloom instances can point to our API worker listeners on the local loopback.
Bloom acts as a Reverse Proxy of its own, and caches read HTTP methods (GET, HEAD, OPTIONS), while directly proxying HTTP write methods (POST, PATCH, PUT and others). All Bloom instances share the same cache storage on a common redis instance available on the LAN, which holds the actual cached data as an hashtable.
Bloom is built in Rust for memory safety, code elegance and especially performance. Bloom can thus be compiled to native code, without the overhead of a garbage-collector or of an interpreter.
Bloom has minimal static configuration, and relies on HTTP response headers served by the API workers to configure caching on a per-response basis. Those HTTP headers are intercepted by Bloom and not served in responses to the Load Balancers. Those headers are formatted as Bloom-Response-*. Upon serving response to our Load Balancers, Bloom sets a cache status header, namely Bloom-Status which can be seen publicly in HTTP responses (either with value HIT, MISS or DIRECT — it helps debug the cache configuration for a client request).
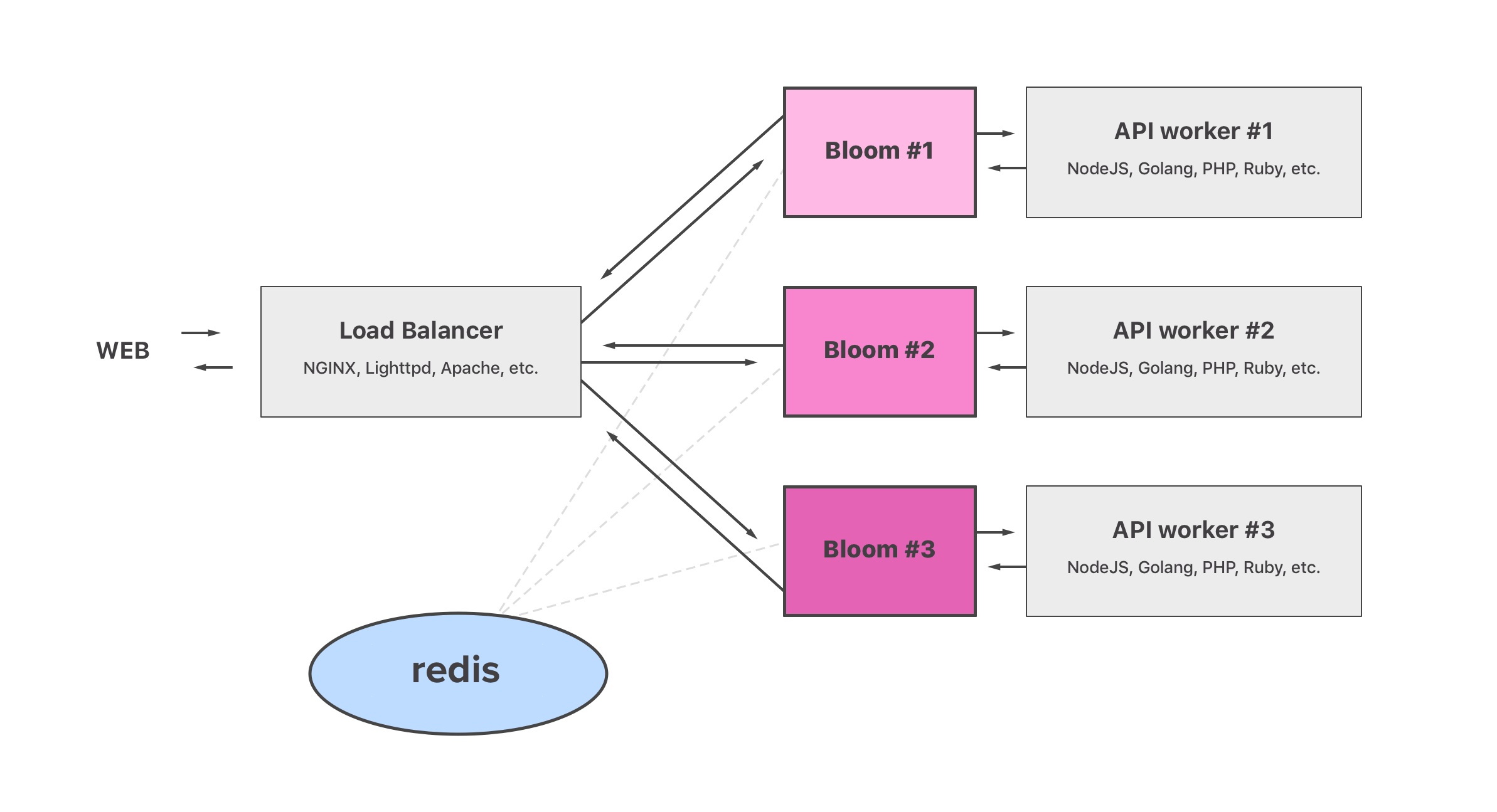
As shown in the schema above, the topology of the internal HTTP network doesn't need to be changed much to accommodate Bloom. Existing Load Balancer rules are kept intact, though instead of pointing to your API workers it points to each Bloom instance that sits in front of each API worker.
Feature List
The major features that Bloom provides are:
- The same Bloom server can be used for different API workers at once, using HTTP header
Bloom-Request-Shard(eg. Main API uses shard0, Search API uses shard1). Thus, we can have a single Bloom instance per physical server, serving multiple services eg. our REST API and a few smaller APIs. - Cache can be tagged as belonging to a bucket, specified in the responses from the REST API using the HTTP header
Bloom-Response-Bucket. - Cache is clustered by authentication token, no cache leak across users is possible, by namespacing based on the
AuthorizationHTTP header. - Cache can be expired directly from REST API workers, via a control channel.
- The caching strategy is configurable per-request, using
Bloom-Request-*HTTP headers in the requests the Load Balancers forward to Bloom.- Specify caching shard for an API system with
Bloom-Request-Shard(default shard is0, maximum value is255).
- Specify caching shard for an API system with
- Caching strategy is configurable per-response, using
Bloom-Response-*HTTP headers in the API responses to Bloom.- Disable all cache for an API route with
Bloom-Response-Ignore. - Specify caching bucket for an API route with
Bloom-Response-Bucket. - Specify caching TTL in seconds for an API route with
Bloom-Response-TTL(other than default TTL).
- Disable all cache for an API route with
- Non-modified route contents automatically get served a
304 Not Modified, lowering bandwidth usage and speeding up user requests (for clients that previously accessed the resource).
About Bloom Control
Bloom can be configured to listen on a TCP socket to expose a cache control interface. The default TCP port is 8811 (it is an unassigned port). Bloom implements a basic Command-ACK protocol.
This way, our API worker (or any other worker in our infrastructure) can either tell Bloom to:
- Expire cache for a given bucket. Note that as a given bucket may contain variations of cache for different HTTP
Authorizationheaders, bucket cache for all authentication tokens is purged at the same time when you purge cache for a bucket. - Expire cache for a given HTTP
Authorizationheader. Useful if an user logs-out and revokes their authentication token.
For convenience, a Bloom Control library has been published for NodeJS, available as node-bloom-control. Bloom Control can be easily implemented for other platforms, as it only requires the farmhash dependency, and the ability to open a raw TCP socket. The JavaScript implementation code is quite readable and can easily be adapted to other languages.
Available commands
The control protocol is trivial. It recognizes the following commands:
FLUSHB <namespace>: flush cache for given bucket namespaceFLUSHA <authorization>: flush cache for given authorizationSHARD <shard>: select shard to use for connectionPING: ping the serverQUIT: stop the connection
Control flow example
An example of the control protocol can be found below.
Notice the HASHREQ / HASHRES exchange, which is used as a check of the control channel client hashing function compatibility. Bloom requires the control client to send the bucket and authorization values hashed in a compact, ready-to-use format. This helps keeping the protocol simple (eg. fixed buffers are used; as arguments don't vary in length for a given command). Thus, to avoid weird hash-related issues when issuing commands, an early compatibility check is done. The reason is the following: farmhash may output different hashes for the same input, when testing on different architectures. If the API runs on a different server / CPU than the Bloom instance (it can happen in some topologies), it may have a different CPU instruction set resulting in different hash outputs.
telnet bloom.local 8811
Trying ::1...
Connected to bloom.local.
Escape character is '^]'.
CONNECTED <bloom v1.0.0>
HASHREQ hxHw4AXWSS
HASHRES 753a5309
STARTED
SHARD 1
OK
FLUSHB 2eb6c00c
OK
FLUSHA b44c6f8e
OK
PING
PONG
QUIT
ENDED quit
Connection closed by foreign host.
Closing Notes
We hope that Bloom will make Crisp scale in a smoother way. Beyond the drastic load decrease of our API workers, we also hope it will decrease the volume of outbound / egress data our Load Balancers put on the network (we're hitting some high numbers here too, in the TiB scale); thanks to the 304 Not Modified feature that only a cache middleware makes possible. This paves the way to client-side caching, which is not a common practice in the world of REST APIs.
We're excited to lead the way in this, and we can't wait to see how it will impact the performance of Crisp on mobile (iOS & Android) on poor cellular networks. We have a lot of users in developing countries that use Crisp on mobile most of the time, eg. to answer questions from their customers — reactivity and reliability is critical for their business.
Note that — in August 2017 — a stable Bloom release has been published. The code that's available on GitHub is working and is being actively maintained, as it is used to run the Crisp production platform.

May 2025 - Product Update
Want to know what the team has done this month? Make sure to read this article.


April 2025 - Product Update
Want to know what the team has been cooking lately? Make sure to read this article!

March 2025 - Crisp Product Update
Want to know what's been cooking at Crisp over the past month? Make sure to read this product update.






