Details on the 22/07/2019 incident and how we are fixing this for the future
On July 22th, Crisp experienced infrastructure issues caused hardware failures with our provider DigitalOcean. We wanted to be transparent about the technical cause of this incident.


On July 22th, Crisp experienced infrastructure issues caused hardware failures with our provider DigitalOcean. Those hardware failures produced a series of events causing two downtimes lasting each approximately 30 minutes.
We wanted to be transparent about the technical cause of this incident and how we are hardening things for the future, to prevent things like that from happening.
A basic introduction to the Crisp Infrastructure
Crisp relies on a micro-service architecture hosted at DigitalOcean. Crisp relies on 60 different servers and most are located in Amsterdam, The Netherlands. Crisp also relies on Cloudflare as a top-level proxy and CDN. Both those providers never (ever!) failed us over the last 3 years.
To be simple, a micro-service architecture is a server design where all the features are divided into multiple simple specialized components. As seen on our status page, those services are replicated to scale more and handle failures better. The micro-services are designed around Crisp features. Some handle notifications, other messages, emails, plugins, helpdesk, contacts, etc. If a single micro-service runtime breaks, Crisp is still up.
Here is a (very) simplified version of the Crisp Architecture:
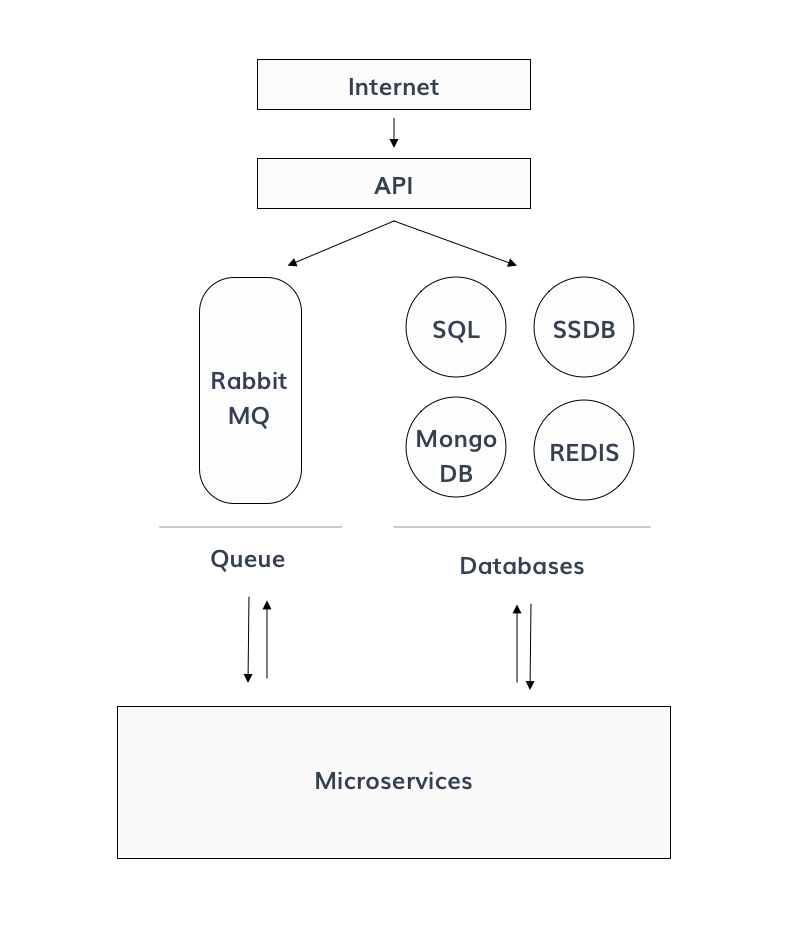
As seen in this schema, micro-services are publishing tasks (message sent/received) using the Queue, and Databases storing/retrieving information using databases.
These components are important to make Crisp running properly.
Of course, our system were designed to handle some failures:
- If the Queue, is not running properly, the systems are stacking their events (like messages) locally, and then it's unstacked once it's up again. If the downtime is too long (like 5 minutes), we can easily create a fresh new queue server and all the events will start to be unstacked again (ie. traffic would be re-routed).
- In case of a failure databases like on MySQL or MongoDB, we have a cache layer so you can still access your dashboard and send/receive messages. The messages are then stored later.
- Redis and SSDB are very similar databases. These databases are designed to store temporary data, for caching or tokens. The major issue with those databases is these are designed to be fast and can't be easily clustered. As these systems can't be easily replicated/shared, the strategy in case of failure is to create a fresh new server and then to migrate the data in few minutes.
So what happened?
13:14 UTC: SSDB is gone
Our team received a monitoring alert as soon as the problem appeared at 13:14 UTC (15:14 local time), caught by our open-source Vigil monitoring system (which we built for Crisp).
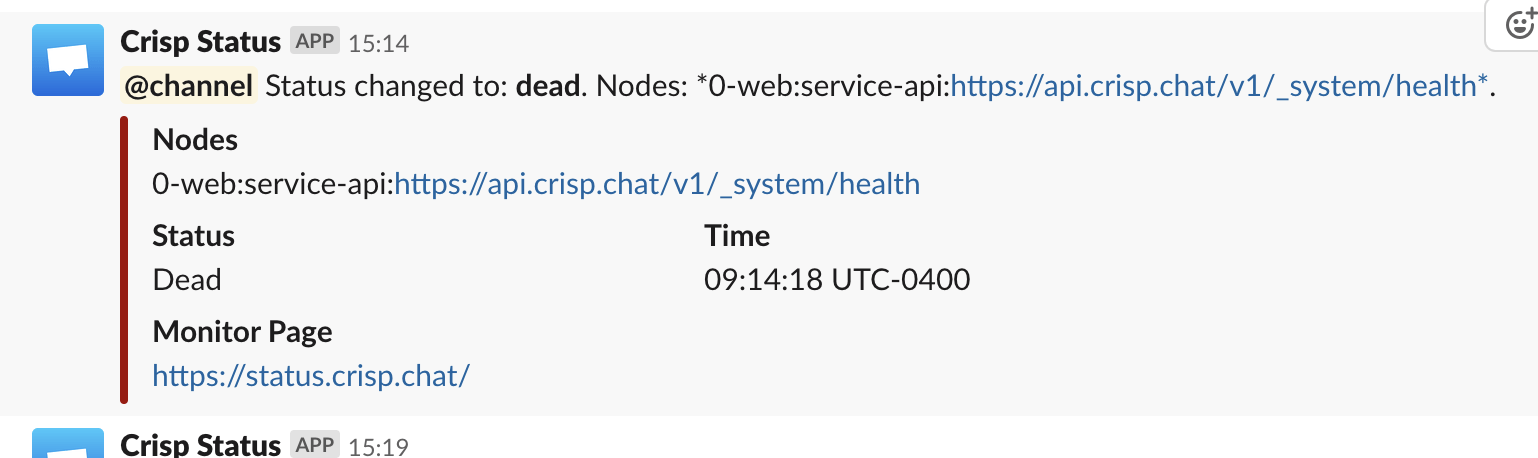
In case of detected failed system, we receive an immediate alert on Slack (which the whole team is notified of). If the outage is still occuring 5 minutes afterwards, the alert is elevated to critical, and dedicated GSM phones start ringing all around (or waking us up at night).
Quickly, we found the impacted host and discovered that this server was hosting SSDB.
We immediately contacted DigitalOcean who was unaware of the situation, by creating a ticket. As their support team was unresponsive, we contacted them on Twitter as well.
Their team informed us of about the issue at 13:34 UTC (20 minutes later).
Thanks for that info. Our engineers are currently investigating issues on that Droplet's host hypervisor.
The backup plan
Meanwhile, we followed the strategy explained in the introduction. We started to deploy a new server using a backup a few minutes after the initial incident.
The problem is DigitalOcean system failed to create a new Droplet (500 errors on their dashboard + event processing delays). It took around 15 minutes to get a server created from a recent backup, which was unable to boot due to a backup restoration error out of our control (the second restoration attempt succeeded, though). Usually, DigitalOcean is able to spin up servers in less than 60 seconds.
The physical machine hosting the original server was fixed by DigitalOcean around 13:40 UTC so we decided to use it again, and delete our newly-restored server.
A few minutes later we received an email alert from DigitalOcean letting us there was an additional planned migration to this server. This migration was announced as "hot" (migrating from a different server with no downtime), and wasn't supposed to fail. As we were used to such migrations in the past, we were confident this would succeed and have no impact.
The Muphy's law couldn't be so right: the hot migration resulted a very slow I/O on the disk, which SSDB depends heavily on. This had the effect to prevent some micro-services to operate properly (eg. chatbox socket systems), and finally overloaded some other more critical micro-services ~20 minutes later (ie. the API system).
We decided then to run again with our backup server. As our backup server was up and running, we expected Crisp to be up again.
Potential VLAN Rate-limiting
At 13:50 UTC, as our system started to be working again, we had a sudden traffic spike. All our customers were reconnecting to the platform around the same time. Our team was expecting this effect. The Crisp App is designed to mitigate this effect and the app automatically reconnects with a random-delay.
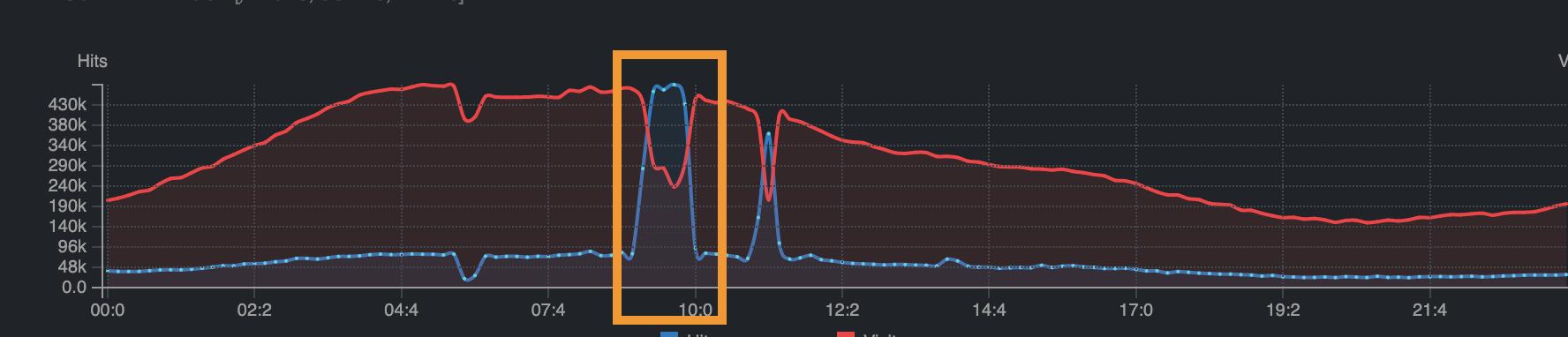
The additional issue is DigitalOcean could detected this spike as a potential DDoS and their system started to rate limit our internal network. Even if not officially acknowledged this time by DigitalOcean, this same problem already happened before. We made an educated guess that some active DDoS mitigation system has been recently installed on their network (ie. a few months ago), as we did not experience such symptoms before.
As the network is rate limited, it means that the micro-services can't talk to each-other anymore using the message queue as most messages are failing to be delivered, while some lucky ones go through. Similar to a traffic congestion on the highway.
Our team decided to stop some services and stop APIs to reduce the internal traffic and go under the radar.
15 minutes later, we progressively re-opened systems one-by-one, and everything went back to normal.
Our plan to prevent this from happening again
Obviously, we are looking at different options to host our servers. DigitalOcean never failed us in 3 years, though over the last few months outages on their side have caused havoc on ours. They failed on four essential points:
- Their servers failed;
- Their monitoring failed (we knew before they appeared to know);
- Their customer support was unresponsive (20 minutes feels like forever);
- Their dashboard failed to create a backup server in time (this used to be fast);
- Their network failed;
On the other hand, we are working to make Crisp more failure resilient. Our micro-service can fail on different points
- Failures on core nodes;
- LAN / Network issues;
- Top-level issues like a Cloudflare outage;
Fault-tolerant databases
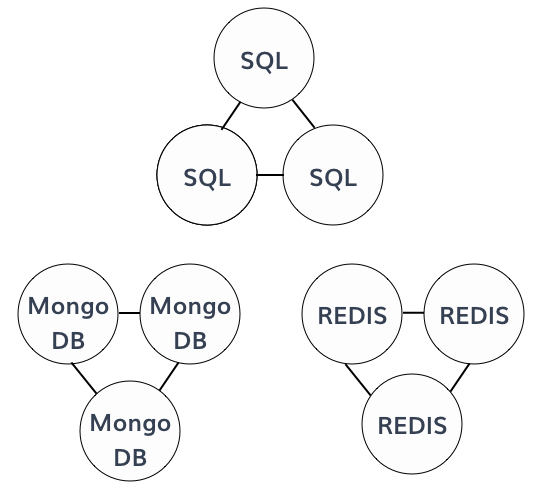
First, we are planning to patch our servers to use local cache strategy when it's possible on some systems like DNS to ensure those systems are still running even if a database is gone.
We are also planning to create database clusters to prevent migrating manually when something goes wrong. This way we are sure a server is ready to handle the traffic.
Fault-tolerant software
We are also planning to launch a safe-mode in our next Crisp 3 release. This way, when a failure happens, we will be able to trigger the safe-mode globally, disabling some non-vital Crisp features, like Campaigns, Analytics, MagicBrowse, MagicType as well as some routes consuming server CPU time. This safe-mode will be focused around messaging features. We want to let you reply to your customers, even if case of a an issue.
This safe-mode could reduce our API traffic from 80%. This mode could potentially help in cases like:
- High-loss on the LAN or public network;
- DDoS attacks;
- A sudden outage (electrical power, hypervisor) on a major part of our systems;
Fault-tolerant network
Crisp previously experiences issues Cloudflare witch had two major incidents recently and caused us troubles as well as many different companies.
Cloudflare acts as our NS server on our domain name crisp.chat. Changes on a DNS level takes a long time. From minutes to days depending from ISPs. As any change to the DNS can't be considered during downtime we are considering a different option.
We are considering using an emergency domain, like crispfailover.com. This domain would be used as secondary and direct access to infrastructure. The Crisp app would be patched to automatically reconnect to those Cloudflare-free endpoints.
This way, in case of downtime on Cloudflare, you would still be able to reply to your customers.
Advanced details for techies
Knowing that some of you may be super-technical, and thus interested about our mitigation and improvement strategies, we decided to be completely transparent with you and share the roadmap of the planned software and infrastructure improvements that we are working on this week and next week:
1. Core infrastructure
- Implement automated high-traffic degraded mode for Crisp apps (front-end) and Crisp micro-services (back-end), temporarly stopping all non-essential features that consume most bandwidth and CPU load, such as MagicType, MagicBrowse and availability (ie. online states). This needs to be implemented in a fault-tolerant way, with a local cache system at the micro-service level, with automated decision making about in which mode the micro-service should put itself (normal or high-traffic) in based on external and internal context of the infrastructure.
- Replicate all current storage backends that are not yet replicated, and build replication capabilities into our OSS search index backend, Sonic.
- Declare some internal backends as non-critical for a request to succeed (eg. internal micro-service request or over-HTTP API request), thus prevening pipelines from waiting indefinitely for a failed backend to respond.
- Implement a last-chance CloudFlare bypass for our HTTP API, Operator app and Chatbox systems (in a once-in-3-years event either CloudFlare DNS or CloudFlare CDN + HTTP fail).
2. Plugin infrastructure
- Split our plugin system in multiple isolated system, per-plugin type; this ensures that a load spike in messaging plugins (Messenger) does not affect eg. automation plugins (Bot);
- Split our plugin HTTP load-balancer in 2 nodes, and do the same for our plugin data storage system (ensuring that if a server goes dark, the whole plugin system stays up);
3. Atlas infrastructure (ie. our Geo-distributed WebSocket system)
- Implement HTTP health checks to our open-source Constellation Geo-DNS server, in order to remove failed IPs from the geographic pool, and serve fallback IPs if a whole region goes dark (eg. re-route traffic to Europe directly, which is slower for most users, but which will ensure the service never goes down);
- Ensure the Constellation DNS server is more tolerant to Redis failures, by being able to re-use expired local records cache in the event of a Redis outage (Redis is used to store our Atlas-related and Email-related DNS records, per-customer);
- Configure more failover VPN tunnels for all our Atlas servers worldwide (ie. if a P2P tunnel fails with our core infrastructure, a failover tunnel will be used);
- Build logics in the chatbox client to avoid opening WebSocket connections when the infrastructure is known to be experiencing exceptional load, which would still allow chats to go through but will not report realtime visitors anymore (eg. for MagicMap and MagicBrowse). This ensures service continuity in degraded mode;

Automated ticket routing: how to get every conversation to the right agent
Manual triage worked when a manager could eyeball every conversation. Now that AI resolves the easy tickets automatically, what's left for your team is the hard, ambiguous residual: exactly the conversations where routing to the wrong agent hurts most.


Unified customer view: how to give every support operator full context before they reply
Most support setups store customer context in pieces: chat here, email there, a note nobody linked. This guide shows what a true unified customer view requires, why fragmented context gets more expensive as you scale.

Ticket escalation done right: how to move issues up the chain without losing context
When AI handles first contact, every handoff to a human should feel like a continuation, not a reset. Here's how to build escalation that carries full context and clear ownership at every step, instead of making customers repeat themselves.












