The Pitfalls of Using LLMs in Customer Service Chatbots
This is the story behind the release of our AI model dedicated to customer service teams. Discover why we didn't opt for a chatbot that takes advantage of LLMs to empower customer service teams.


The release of ChatGPT in December 2022 sparked a new revolution in the world of artificial intelligence. What many believed to be impossible for a long time was now possible: having a conversation with a robot powered by artificial intelligence (AI), capable of answering all types of questions, almost perfectly.
These new AI models, called LLMs (Large Language Models), can actually reason coherently with textual data, have a strong synthesis capacity, and finally, are able to understand human intentions and make simple decisions.
Many initiatives are born from this revolution. As an example, check this open-source attempt to make GPT4 autonomous: AutoGPT.
This new AI revolution has launched a new hype, and it is believed that the gold rush of Blockchain is now moving towards artificial intelligence.
At Crisp, we offer a SaaS software that allows multi-channel customer service (Livechat, Email, Messenger, Whatsapp, etc), alongside many other features to empower customer service teams.
As CEO of Crisp, I am often asked about what impact AI would have on customer support. Some experts mention that up to 80% of jobs could be impacted by AI, with customer service mentioned in the top 5 professions that could be contested in the medium term.
Since the release of GPT3 in 2020, we have extensively tested the capabilities of these new LLMs and what they could solve in terms of customer support tasks for our customers.
We have made exciting discoveries, and guess what?
It might be counter-intuitive but ... LLMs are rather poor at creating customer service chatbots. At least, it depends on how we use them.
Let's decode.
How customer service chatbots work (currently)
Providing factual and useful information is paramount in the field of customer service. Traditional chatbots that appeared in the early 2000s mostly offer a very disappointing experience to customers, as they don't really understand what the customer needs. Often used by large companies (airlines, internet service providers, insurance companies), these chatbots have mainly been employed to achieve economies of scale, without understanding that the best customer service in the world is when the customer has no problem.
In fact, these chatbots are strangely similar to the functioning of IVR (Interactive Voice Response) systems. You know the kind of toll-free number you call and are asked to press 2, then 1, then 3, only to be told that the information is on the website.
Well, that's how chatbots currently work.
Going deeper, traditional chatbots work mainly in the following 3 ways:
Scripted: This is the simplest form of chatbots. The customer is qualified through a list of choice buttons (for example: after-sales service, product return, refund request). The system then responds with pre-written answers, conditioned on the user's choices. The problem is that users often do not find what they're looking for among the choices offered.
Pattern matching: User's question is analyzed by an NLP (Natural Language Processing) module of varying complexity. An intention detection is done, and the chatbot pulls its answers from a pre-recorded answers database. These systems can be useful, but it is impossible to follow up on the answer proposed by the chatbot.
Knowledge bases: Some bots draw their answers from a knowledge base. They analyze the question and suggest an article that could solve the user's problem.
The main issue with these chatbots is that they only effectively answer around 12% of customers. Why? Because these systems are designed to be factual and answer a finite and known set of questions in advance. This implies creating a resource for every question a customer can ask.
To answer 20% to 30% of the questions, it then requires solving the long tail of questions, often writing 30 to 100 times more answers in the FAQ. This makes long-term maintenance very complex, especially for SMBs.
Many people think AI will replace customer service jobs.
— Baptiste Jamin (@baptistejamin) February 21, 2023
Our at research @crisp_im tells AI won't be able to help on more than 30% issues.
Using ChatGPT to create an AI-powered customer support chatbot
This is the question we asked ourselves at Crisp and we tested it for you. As we have seen earlier, modern LLMs such as GPT are extremely good at answering common sense questions from public data.
However, the datasets used to train these models are made from public data (CommonCrawl). That's why ChatGPT can be very good at, for example, troubleshooting iPhone issues.
However, unless your company is Apple, or well-known, there is virtually no chance that ChatGPT can adequately solve your customers' problems.
And that's quite normal. If you hire a random person off the street tomorrow and put them in front of your customers, they would behave roughly the same: this person has not been trained about the specifics of your company.
One solution would be to re-train a model from scratch to solve company's problems. Such solution would cost at least $300,000 per company, which would be far too expensive.
Another solution, which is becoming increasingly popular, is using language models' reasoning abilities. What we call "few-shot" learning.
Few-shot learning refers to the ability of connecting a language model to a vector search base, which allows searching for answers or useful resources to solve a given question (LangChain is one of the frameworks that popularized this method). The model then uses these resources and crafts a possible answer.
In a nutshell, it is like doing a Google search on your own data and providing the top 10 results to ChatGPT to get the answer.
At Crisp, we tested this methodology. It was however really important to have real questions asked by customers.
We tested this method using 3 main data sources:
Our website: we scraped our own website and vectorized its content. About 3,000 pages.
Our help center and developer documentation: we injected each article from https://help.crisp.chat which counted around 500 articles.
Last but not least, all the conversations we had with our own clients: several hundred thousand conversations!
So we took a sample of those several thousand conversations we had with our customers and picked random messages.
The question we asked ourselves when labeling the data was:
From the labeling data set, we trained a small classification model, which allowed us to filter, from several hundreds of thousands of real Crisp related conversations, questions that would be answered by new our bot. This allowed us to compose a dataset of 50k relevant questions to test this chatbot.
And the results were very interesting!
Using our website as a data source to create a customer service chatbot
First of all, we saw that the model hallucinates a lot on real questions from our own customers. One of the reasons is that a website is mainly about storytelling/marketing. Copywriting is meant to convince potential buyers.
As well, real customer questions are often about information that is not present on the website. This is another reason why the model hallucinates on the vast majority of questions.

Using our help center as a data source to create a customer service chatbot
Similarly, we tested using articles from our help center at https://help.crisp.chat/. Answers are much more accurate, however, the system still suffers from hallucinations. For example, when a user asks if we have a Microsoft Teams integration, the system tells we have one, while we do not offer one.
The reason for this hallucination is related to the fact that we offer a Slack and Discord integration. The system therefore judged it possible that we have a Teams integration because of the two other ones.
Using our Crisp conversations as a data source to create a customer service chatbot
And finally... vectoring our support conversations. This is precisely where we obtained the most interesting results, with an accuracy of about 60% to 70%.
The reason is in fact simple: past conversations with real customers contain a lot of interesting things, nuances, and contradictions. And most importantly, it's a much larger data source.
This data source is also very interesting because it suffers much less from hallucinations, compared to the other two sources.
However, this solution has a major problem: it is possible to leak customers' personal information if end customers interact with such an AI chatbot.
We have tested supervised chatbots trained on our data, with real-customers in the conversation, and our results have been rather mixed, with many inaccuracies.
Using AI as Customer Service Co-pilots
Productivity for customer service teams is something vital for companies, as well as for end-customers, who're expecting ever faster answers.
Macro responses have been used in customer service for years. You know! Macro responses are these ready-made responses used to make customer service teams more productive. It's like a database of predifined answers.
Customer support agent types !lost_password, and automatically, a 3-line message comes up, explaining how to solve the support.
We started from the idea that if a large language model can be effective in the order of 60 to 70% in answering questions, then it would make a perfect system not to assist customers, but to support customer service agents.
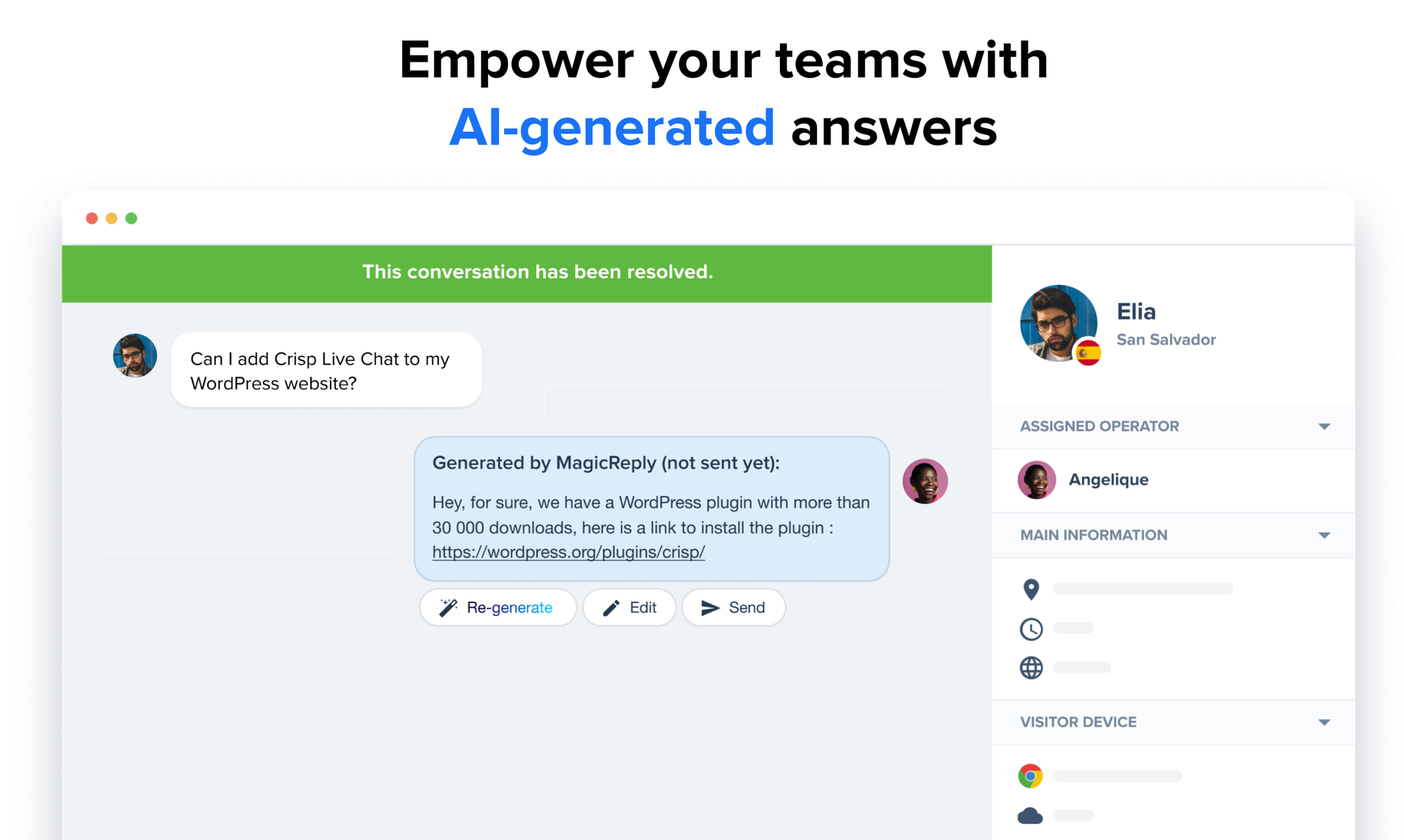
"Do you support bank transfer payments?"
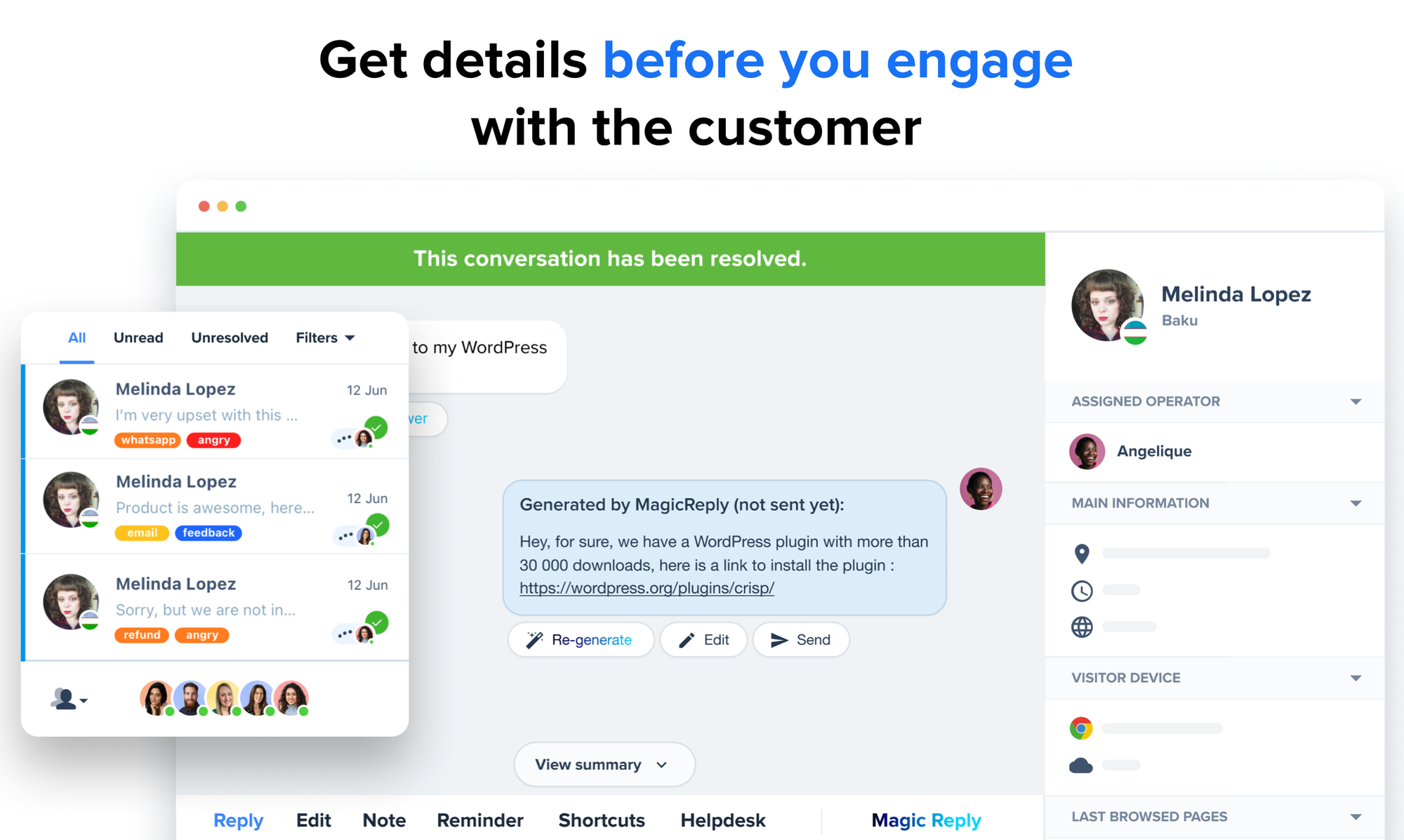
Such a question automatically triggers our new AI assistant for customer service teams. In less than a second, the answer is ready to be sent. The customer service agent is free to send it or not, or edit it to provide a better, personalized answer.
Personally, I believe much more in this vision: humans and AI collaborating together, not one replacing another.
First of all, I think that the customer relationship should be human. Your customers don't want to talk to robots. Talking to customers is not just a cost, it's also an opportunity, a way to create lasting relationships with them, to get new ideas for your product and a lot more.
At Crisp, we believe that the AI/Human collaboration can be very interesting and this is what fuels our vision on that subject.
The robot can compare hundreds of millions of information in a fraction of a second. On the other hand, humans have a real capacity for persuasion and empathy. Such system is very convenient.
For example, we are often asked at Crisp if it is possible to change a feature or add a label, change our Chatbot color, the language settings, etc. With such system, in a few milliseconds, the robot suggests the right resource. On this kind of use case this is super useful.
But here is the truth:
The real value of LLMs in customer service is to solve more complex problems and bring a little creativity to customers who ask tricky questions.
Building our own LLM to serve our vision
To make the dream come true and allow customer service teams to benefit from an AI-powered virtual assistant, we had to build it from scratch. Here is how we did.
Our (good reasons) not to use OpenAI
There are multiple reasons that led us to not use OpenAI models.
- Private Data: our use-case requires to store and to embed conversational data. We don't believe this data should be shared to any third party provider: it should stay private and internal to Crisp only.
- Cost: our use-case requires to perform many parallel inferences, with at least 40k tokens per second. Using OpenAI would be pretty expensive and that can't work with our pricing model.
- Performances: while OpenAI's models are incredibly powerful, they are general-purpose models. They can write poems, compose music, answer factual questions, generate software code, and more. However, in some specific applications, a fine-tuned model might outperform them. There are plenty open-source models than can be easily fine-tuned using frameworks like DeepSpeed or LLM Foundry.
Our use-case for customer service
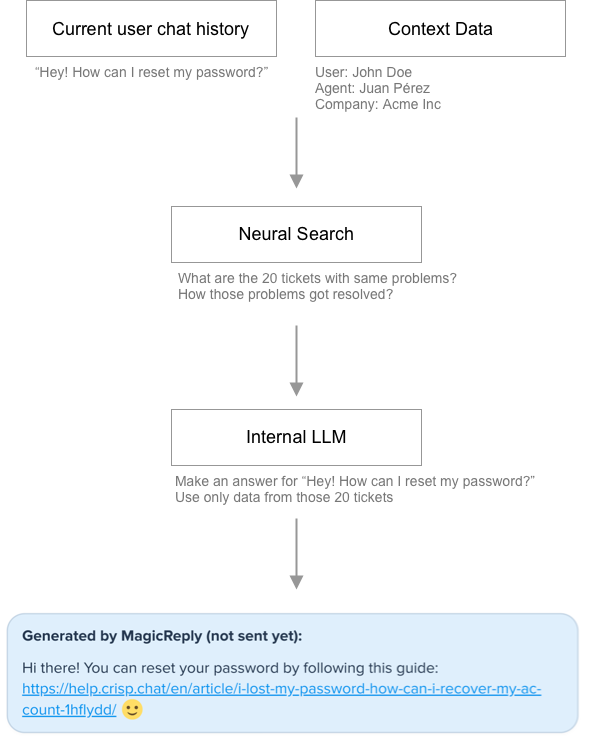
Our system behaves like a copilot for customer support agents. As an input, it takes a user question, as well as contextual data.
We then use a Vector Search system to retrieve how conversations with the same problem/question got resolved. We then feed 20 conversations to an internal LLM.
The generated answer is created under 1 second and is displayed to the customer support agent.
Fine-tuning the Large Language Model
Fine-tuning the model required to build an extensive dataset with qualified prompts. We extracted around 10 000 questions that were asked by our customers, and re-created prompts with 20 similar conversations that were resolved.
A human answer for each prompt (so 10 000 answers) was then generated by our team using a specific methodology, especially to mitigate hallucinations.
The methodology we used was to behave like a customer support intern during his first day:
- We asked our labellers to only respond using data from prompts and forbid to use their own knowledge about our product. For instance if the question is "What is the price for Crisp?", the labeller should only answer if the information is mentioned in the prompt and not search on Google to craft an answer.
- We asked our labellers to rephrase, not to pick answers from prompts. All data shall be rephrased.
- We asked our labellers to respond as if they were in front of customers.
- We asked our labellers not to bring any judgment. Is X better than Y? This is subjective. For instance if the question is "Is Crisp better than a specific competitor?", we should not respond to this, because the model won't align properly to use-cases being different than our own one: we want to make 1 model for many companies.
- We asked our labellers not to respond to questions when context was missing
All prompts were then reviewed and we removed answers that were not complying to our labelling rules.
The dataset was then filtered with 75% answerable questions and 25% unanswerable questions.
Finally, we fine-tuned Flan T5 XXL using 8 Nvidia a100 with 80 gigs each using the DeepSpeed framework.
Currently renting 8x a100 GPUs with 80 gigs of VRAM for @crisp_im 🤫 pic.twitter.com/n6uJdR6Qiu
— Baptiste Jamin (@baptistejamin) April 24, 2023
Optimizing our large language model
Open-source models are mostly made by researchers and are not optimized for inference. Right now, most models are using 32 bits tensors, and the best way to run models faster is to "quantize" those using 16 bits, 8 bits, or even 4 bits!
Most GPUs have a 2x ratio for each tensor units. For instance, you can compute 2 times more 16 bit tensors than 32 bit tensors, 2 times more 8 bits than 16 bits, etc.
In the end, it is all about performance so compressing a model to 4 bits can make a model 8 times faster.
There are different compression methods available. The most promising one being GPTQ compression.
Finally, we discovered that most enterprise grade GPUs like (Nvidia A100) perform actually slower for inference, compared to their consumer grade counterparts.
For instance, a RTX 3090 GPU performed x4 times faster than a Nvidia A100 on our compressed model. One of the reason is that memory bandwidth is a bottleneck for LLMs, and consumer grade GPUs have a better memory bandwith than their enterprise-grade counterparts.
Today's discovery: Consumer-grade GPUs like the RTX 3090 are not only cheaper but also outspeed enterprise-grade GPUs like a16/a40/a100 for a fraction of the price.
— Baptiste Jamin (@baptistejamin) May 31, 2023
Introducing our AI-Powered Virtual Assistant for Customer Service
We are pretty satisfied with the result, and we have been testing our new LLM internally for the past few months. It allowed us to reduce our response time by 50%.
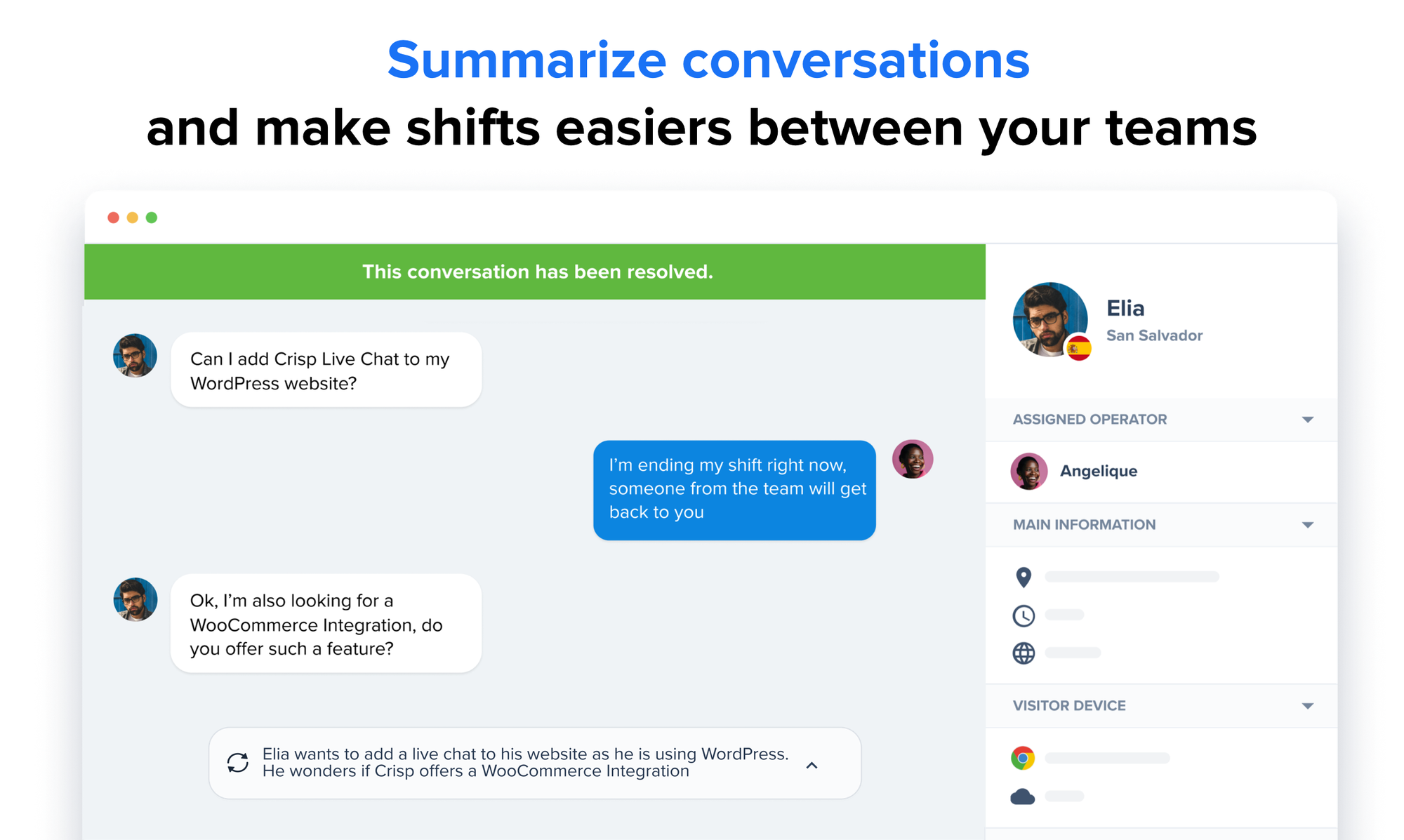
Crisp not only generates pre-written and dynamic answers, but also provides: speech-to-text, translation, and summarization.
A very interesting thing with this model is that it can work for most industries, whether you're working in e-commerce, education, SaaS, gaming, non-profit or travel, ... it can adapt!
Possibilities offered by our Virtual Assistant
Answer
Summarize
Transcribe
Qualify
Want to know more? get in touch here to request an access to our beta:
 Crisp IM SAS
Crisp IM SAS

Automated ticket routing: how to get every conversation to the right agent
Manual triage worked when a manager could eyeball every conversation. Now that AI resolves the easy tickets automatically, what's left for your team is the hard, ambiguous residual: exactly the conversations where routing to the wrong agent hurts most.


Unified customer view: how to give every support operator full context before they reply
Most support setups store customer context in pieces: chat here, email there, a note nobody linked. This guide shows what a true unified customer view requires, why fragmented context gets more expensive as you scale.

Ticket escalation done right: how to move issues up the chain without losing context
When AI handles first contact, every handoff to a human should feel like a continuation, not a reset. Here's how to build escalation that carries full context and clear ownership at every step, instead of making customers repeat themselves.












