9 Tips to Improve Your Software from the Crisp Team
At Crisp, we are making a SaaS software to improve your customer relationship. Featured on ProductHunt in December, we had a growth from 20 to 750 websites in a month. It would not be possible without some tricks. 1 : Workflow automation At Crisp we use Gitlab as code hosting. Gitlab is free and open-source and provides many integrations to make your workflow the best. We use Gitlab CI to automate build and testing. Our codebase is based on Javascript (ES6), and we have many projects. It’s imp

At Crisp, we are making a SaaS software to improve your customer relationship. Featured on ProductHunt in December, we had a growth from 20 to 750 websites in a month. It would not be possible without some tricks.
1 : Workflow automation
At Crisp we use Gitlab as code hosting. Gitlab is free and open-source and provides many integrations to make your workflow the best.
We use Gitlab CI to automate build and testing. Our codebase is based on Javascript (ES6), and we have many projects. It’s important to our team to have coding style/rules. We code as one developer and we use Check-Build to test each commit.
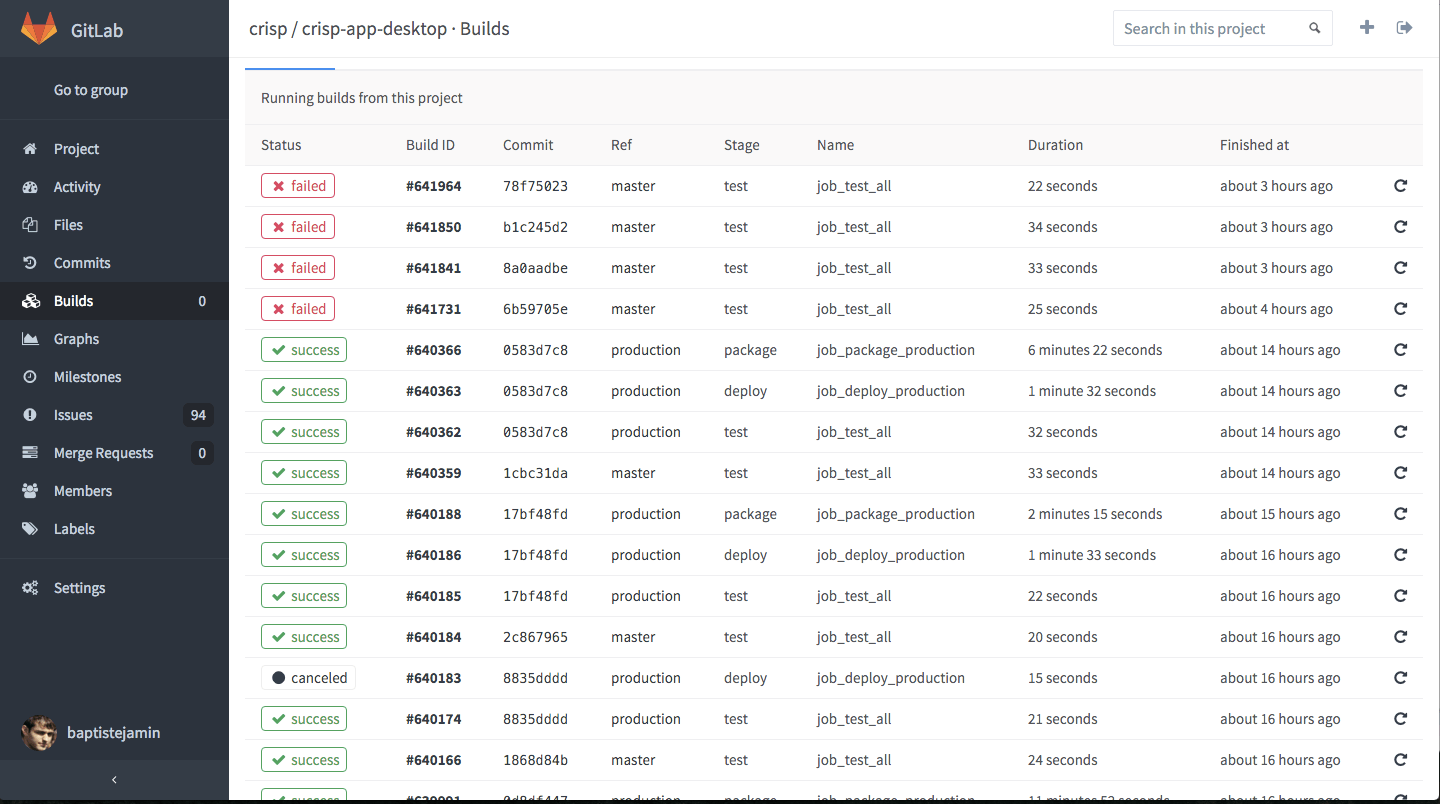
Pushing to production is really simple. We have a production branch. We just have to merge to master branch to production to deploy. Easy!
2 : We use micro-services
And it’s not a buzzword! You maybe heard about it, but micro-services are really popular today. Why?
Because it’s changes your mindset in making software. Each micro-service is based on 500/700 lines of code. It’s easier to a new developer to understand your codebase. “Ok, I have to talk with the Slack API. So, I do a slack-endpoint”. So when I have issues with Slack, I know that it’s into the slack-endpoint.
At Crisp, we use AMQP with RabbitMQ, a nice AMQP implementation, made in Erlang. We have producers, and consumers. When a user sends a message on Crisp, 5 workers may be impacted (to store into DB, sending e-mail, notify on Slack, websockets, etc).
It’s like sharing functions betweens different softwares. Each worker manage some events. For instance, from a worker i can do “slack:send_message”, with an object, and it’s dispatched to slack workers, and these do the job.
AMQP is great to improve our scalability!
Because we can boot twice the same worker and we can consume messages. That means that if I have 2 slack workers, only one will receive the message. And if I kill one, the other will take all the messages.
And no longer problems with TCP listening (HTTP), and Redis broadcasting.
AMQP jobs are transactions. If all my Slack workers are down, when I boot one, it’s consume all the pending jobs.
Turning our software into microservices is great because we can use several languages: Ruby, Javascript, Java, Rust, we don’t care!
Another great thing is that there is no downtime. If we want to update the slack worker, push it to production, it’s boot a fresh new worker, and kills the old one. No downtime with AMQP.
It’s depends from the problem, the productivity etc. And if a worker running Javascript have scaling issues, we can recode it in Go or whatever else. 500/700 lines to recode. Not so much!
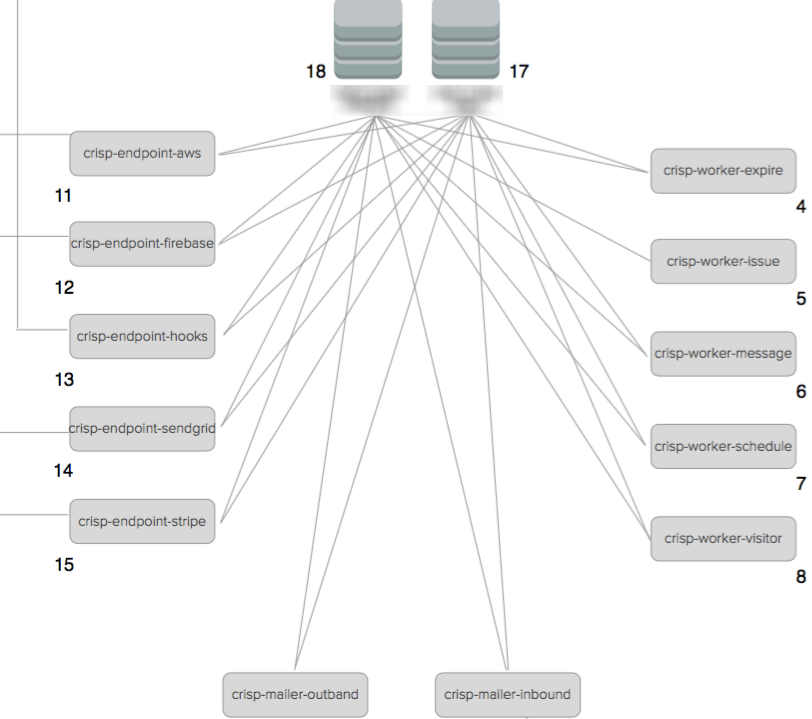
3 : We turn parts of our software into libraries
Ok, so if I use micro-services, I may have several workers. No problems, you can do libraries!
At Crisp, we use private NPM repositories, so we can share code between workers. For instance, we use Loggly as logger at Crisp. This is common to each worker. So it’s in a common library. So if we want to change our logger, we just have to update the library. Easy!
4 : We Deploy fast, we deploy often
We avoid big updates. Both you and me knows that it can be a huge fail on a “Friday push to prod”.
At Crisp, we push to production 20 times a day, and people don’t know that.
It’s good because we can resolve small bugs, improve the software every day. And if we have a problem, we just have to revert. It’s fast.
5 : A problem, a library
Developers are really lucky today. To code complex things, we just have to choose the right library/middleware on GitHub.
If we want to send e-mails, we use a library. If we want to plug an API, we use a library!
6 : We monitor everything
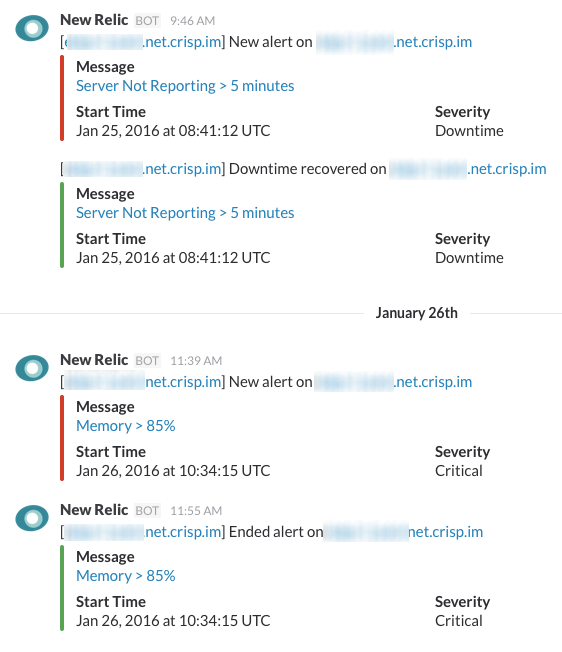
At Crisp, we use New Relic to monitor our servers and Redsmin to monitor our redis clusters.
Our Relic is plugged to our Slack so we can be notified on problems.
7 : No spof in our team.
Dear CTO, can you update the FTP server with the last version with the attached zip file?
Noooooo!
The hugest SPOF (Single Point of Failure) in many teams is the CTO. Everybody at Crisp can push in production, and in case of problem, we can revert.
If you, CTO, is reading this article, your job is to build great tools and doing technical choices for your team.
8 : We eat our own dogfood
At Crisp, we use Crisp everyday, so that we know problems, bugs, and things to improve. If things are not great for us, we improve it.
9 : We have great tools to develop on our computers
Think about your first intern:
You should Git clone project A, B, C, D, E, install Elastic Search, PostgreSQL, here are the config files.
What is Git?
At Crisp we have really great internal tools, so everybody can install it’s own Crisp on it’s own computer. It’s just a line of code. it’s installs the right repos, the right softwares, the right updates, the right aliases.
How to boot the infra?
- crispify-local
How to update the infra, and boot it?
- crispify-remote
How to shutdown the infra?
- decrispify
Conclusion
Thank you for reading, and don’t forget that a good software is made with a good workflow :)

May 2025 - Product Update
Want to know what the team has done this month? Make sure to read this article.


April 2025 - Product Update
Want to know what the team has been cooking lately? Make sure to read this article!

March 2025 - Crisp Product Update
Want to know what's been cooking at Crisp over the past month? Make sure to read this product update.






